火车头采集软件的插件支持多种语言开发,如php、c#、python,这里以 python 作为开发语言编写插件
但从官方文档来看,没有找到很详细的插件编写手册,仅有c#版本的 https://www.locoy.com/index/guide#插件说明文档.html
从网上搜索到的资料来看也没有很详细的介绍,但都是在如下的一个框架基础上编写
# -*- coding: utf-8 -*-
from w3lib import html
from bs4 import BeautifulSoup
from scrapy.selector import Selector
from urllib.parse import urljoin
from urllib import parse
import sys
import json
import requests
if len(sys.argv) != 5:
print(len(sys.argv))
print("命令行参数长度不为5")
sys.exit()
else:
LabelCookie = parse.unquote(sys.argv[1])
LabelUrl = parse.unquote(sys.argv[2])
# PageType为List,Content,Pages分别代表列表页,内容页,多页http请求处理,Save代表内容处理
PageType = sys.argv[3]
SerializerStr = parse.unquote(sys.argv[4])
if (SerializerStr[0:2] != '''{"'''):
file_object = open(SerializerStr)
try:
SerializerStr = file_object.read()
SerializerStr = parse.unquote(SerializerStr)
finally:
file_object.close()
LabelArray = json.loads(SerializerStr)
# 以下是用户编写代码区域
if(PageType == "Save"):
pass
else:
LabelArray['Html'] = '当前页面的网址为:' + LabelUrl + "\r\n页面类型为:" + PageType + \
"\r\nCookies数据为:"+LabelCookie+"\r\n接收到的数据是:" + LabelArray['Html']
# 以上是用户编写代码区域
LabelArray = json.dumps(LabelArray)
print(LabelArray)
插件开发主要工作是基于代码中的 if(PageType == "Save") 区域进行代码编写
比如要实现抓取页面中的文件下载地址,但是该地址并不是页面上提供的 href 地址,而是要经过重定向后才得到
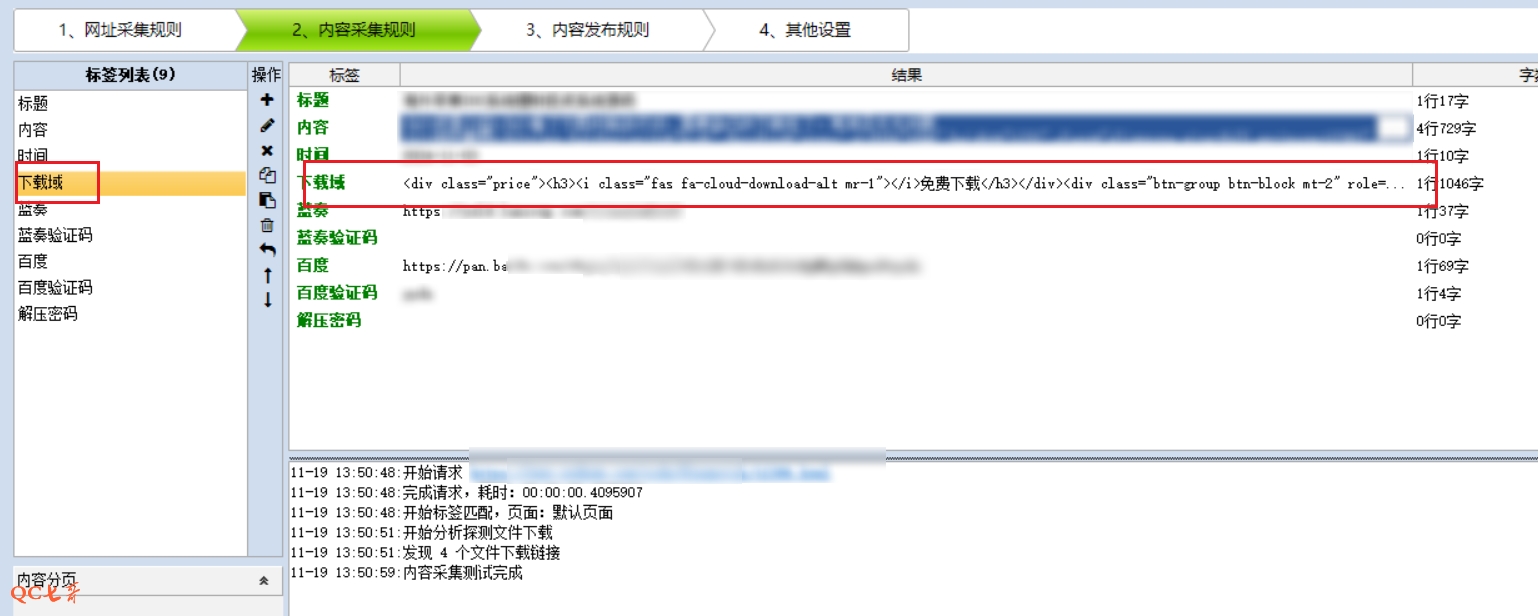
而且下载的这部分 html 内容通过配置也不好定位出来,那么先将该部分 html 通过 xpath 提取,保存到 “下载域” 字段中
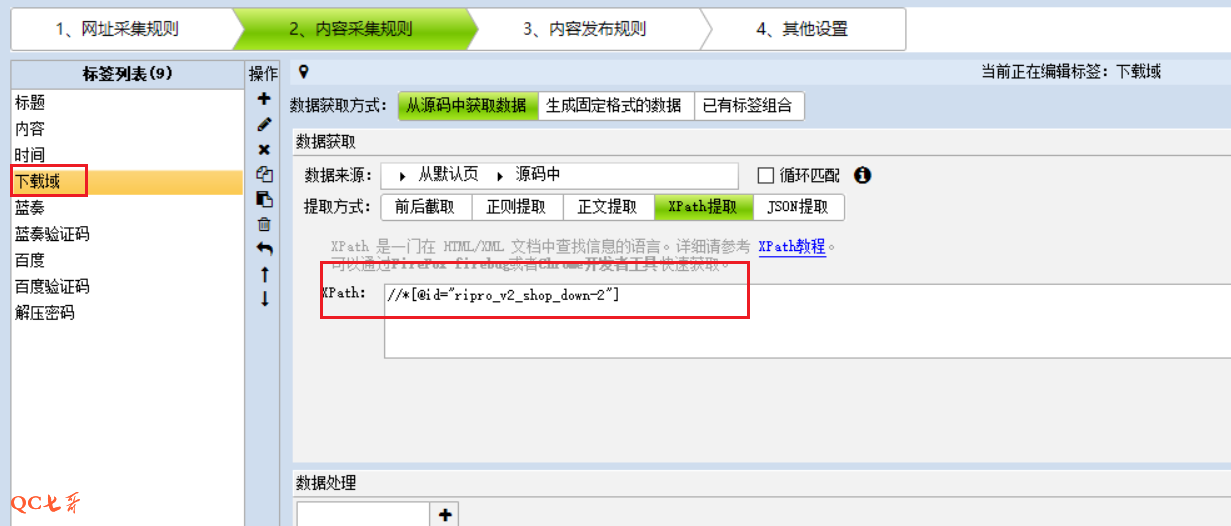
然后再通过插件中的 python 代码来对 “下载域” 文本进行二次加工解析,最终解析得到我关心的所有字段
最终完整的 python 插件代码如下
# -*- coding: utf-8 -*-
from w3lib import html
from bs4 import BeautifulSoup
from scrapy.selector import Selector
from urllib.parse import urljoin
from urllib import parse
import sys
import json
import requests
def getRedirect(url):
response = requests.get(url)
return response.url
def getDownloadInfo(text):
soup = BeautifulSoup(text, 'lxml')
divs = soup.find_all('div')
bdurl = ""
bdpwd = ""
lzurl = ""
lzpwd = ""
for div in divs:
if div.get_text().find("百度") != -1:
link = div.find('a')
if link != None:
href = link.get('href')
bdurl = getRedirect(href)
button = div.find('button')
if button != None:
passwd = button.get_text(strip=True)
bdpwd = passwd.strip()[-4:]
if div.get_text().find("蓝奏") != -1:
link = div.find('a')
if link != None:
href = link.get('href')
lzurl = getRedirect(href)
return bdurl, bdpwd, lzurl, lzpwd
if len(sys.argv) != 5:
print(len(sys.argv))
print("命令行参数长度不为5")
sys.exit()
else:
LabelCookie = parse.unquote(sys.argv[1])
LabelUrl = parse.unquote(sys.argv[2])
# PageType为List,Content,Pages分别代表列表页,内容页,多页http请求处理,Save代表内容处理
PageType = sys.argv[3]
SerializerStr = parse.unquote(sys.argv[4])
if (SerializerStr[0:2] != '''{"'''):
file_object = open(SerializerStr)
try:
SerializerStr = file_object.read()
SerializerStr = parse.unquote(SerializerStr)
finally:
file_object.close()
LabelArray = json.loads(SerializerStr)
# 以下是用户编写代码区域
if(PageType == "Save"):
text = LabelArray["下载域"]
bdurl, bdpwd, lzurl, lzpwd = getDownloadInfo(text)
LabelArray["百度"] = bdurl
LabelArray["百度验证码"] = bdpwd
LabelArray["蓝奏"] = lzurl
LabelArray["蓝奏验证码"] = lzpwd
else:
LabelArray['Html'] = '当前页面的网址为:' + LabelUrl + "\r\n页面类型为:" + PageType + \
"\r\nCookies数据为:"+LabelCookie+"\r\n接收到的数据是:" + LabelArray['Html']
# 以上是用户编写代码区域
LabelArray = json.dumps(LabelArray)
print(LabelArray)