火车头采集是一个很强大的采集工具,加上支持插件的开发,对于大部分网页站点的采集工作都能出色的完成
火车头插件的开发也很简单,可以参考我的另一篇文章 火车头采集插件开发
这里记录在使用采集工具的过程中一些关键操作,以便查阅
新建采集任务,为了方便管理,建议新建目录,然后选中目录,再点击 “+” 进行新建任务
新建任务后,打开一个配置窗口如下
左下角可以填写当前的任务名称,点击右下角可以将当前的配置进行保存
对于火车头工具,一个采集任务主要有三个步骤,下面按这三个步骤来进行说明
1、网址采集规则
大部分站点都是多级结构,如有一级的目录页面,目录页面下有多个文章标题,点击标题打开文章页
比如 CSDN 的博客,这个就是目录页 https://blog.csdn.net/weixin_53109623
在目录页的下面,每个标题都对应一个文章链接,点击文章标题打开的页面就是文章内容页
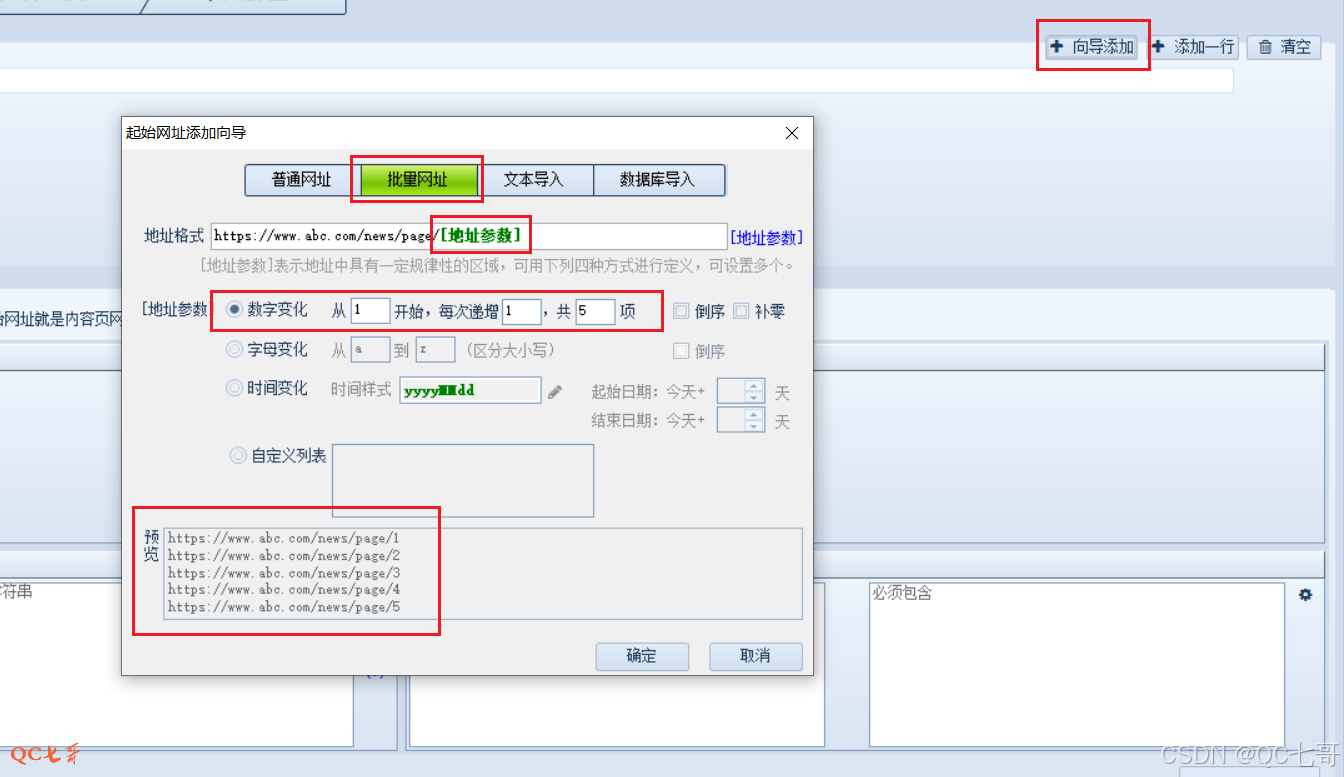
如待采集目录页面网址为 https://www.abc.com/news/page/1 ,链接的 1 为首页,以此递增直到采集完毕为止
可以使用右侧的向导添加,批量网址,然后输入目录网址,将 1 替换为[地址参数](点击右侧地址参数生成)
范围根据实际的采集目录页面进行设置,比如这里设 1 到 5 ,下面预览就会生成 5 个目录页面
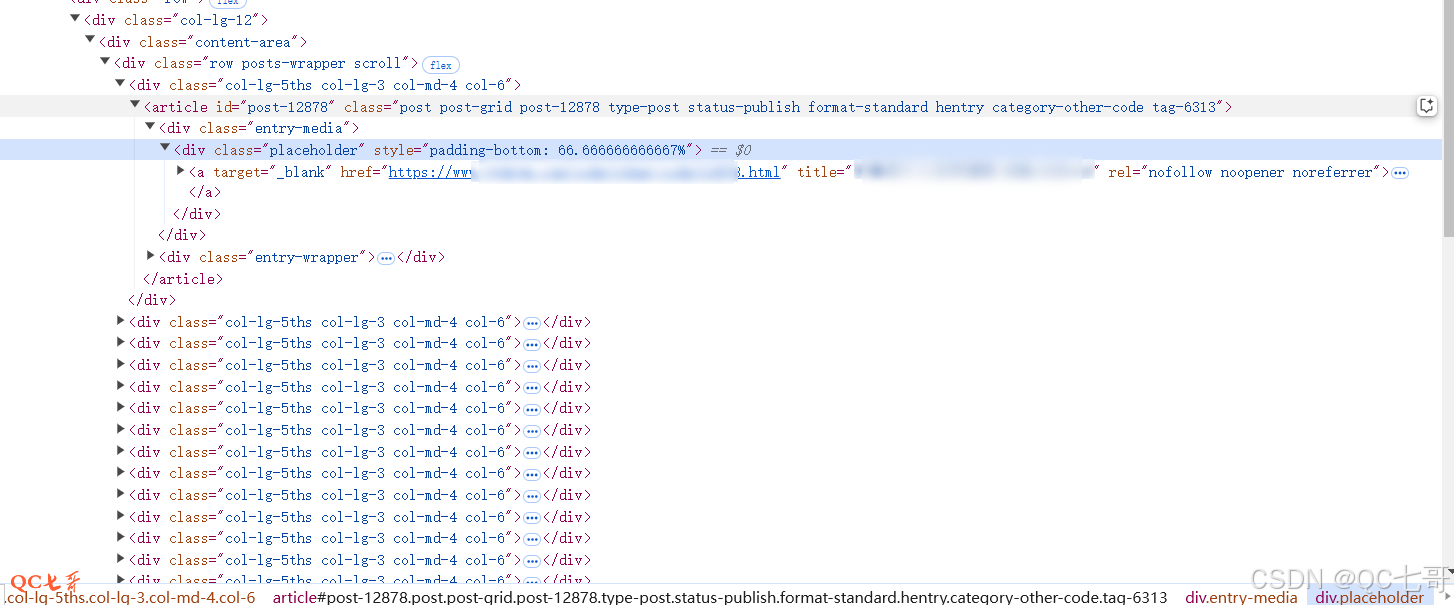
浏览器打开目录页面, F12 查看每一篇文章标题对应的链接,可以得到文章的通配地址 https://www.abc.com/news/()/().html
火车头中使用 (*) 进行通配,上面的通配地址可以适配 https://www.abc.com/news/china/123890.html 类似的网址
在网址采集规则 “设置区域” 第四个框上输入通配地址,表示必须包含,配置完信息如下
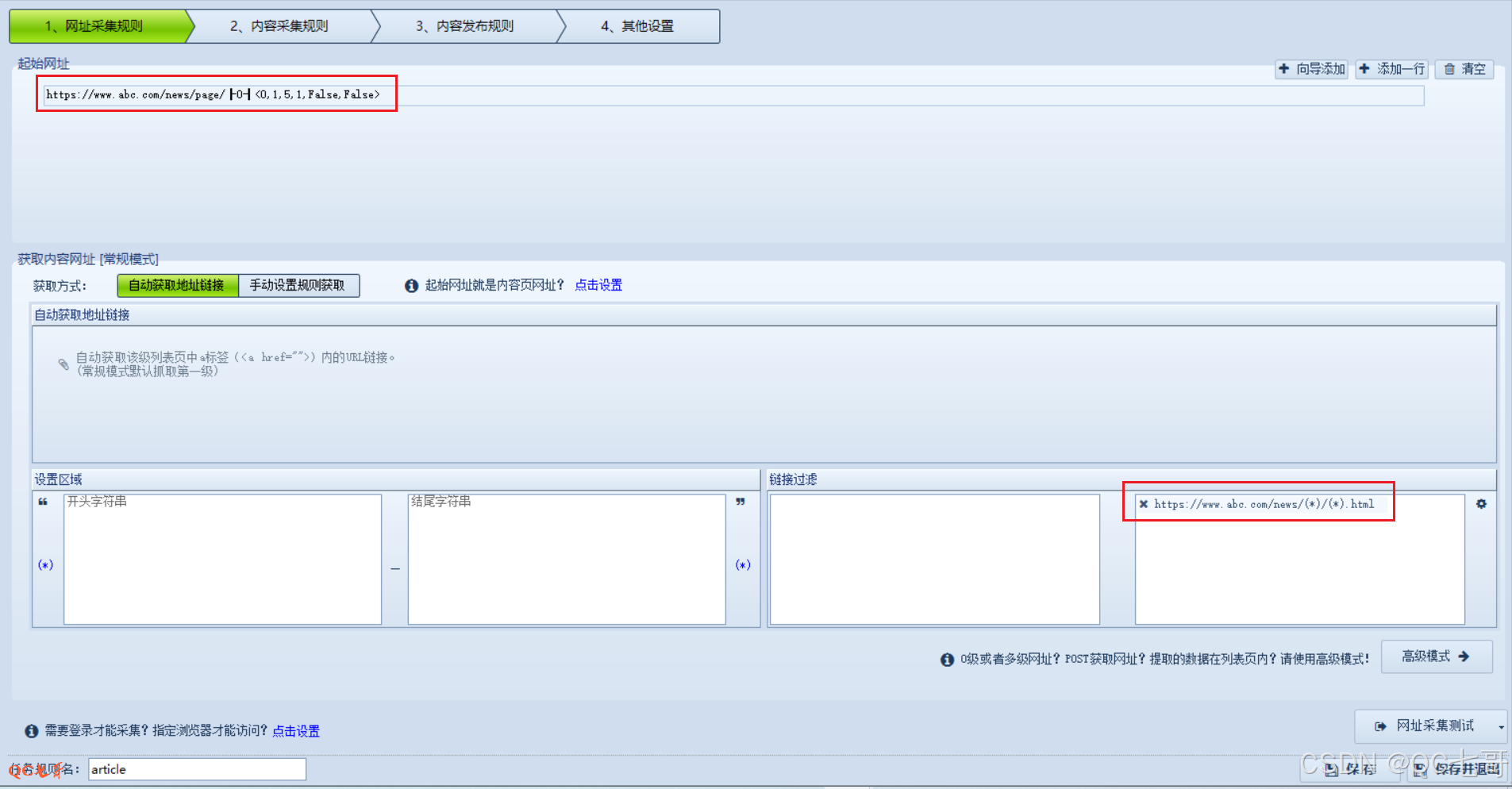
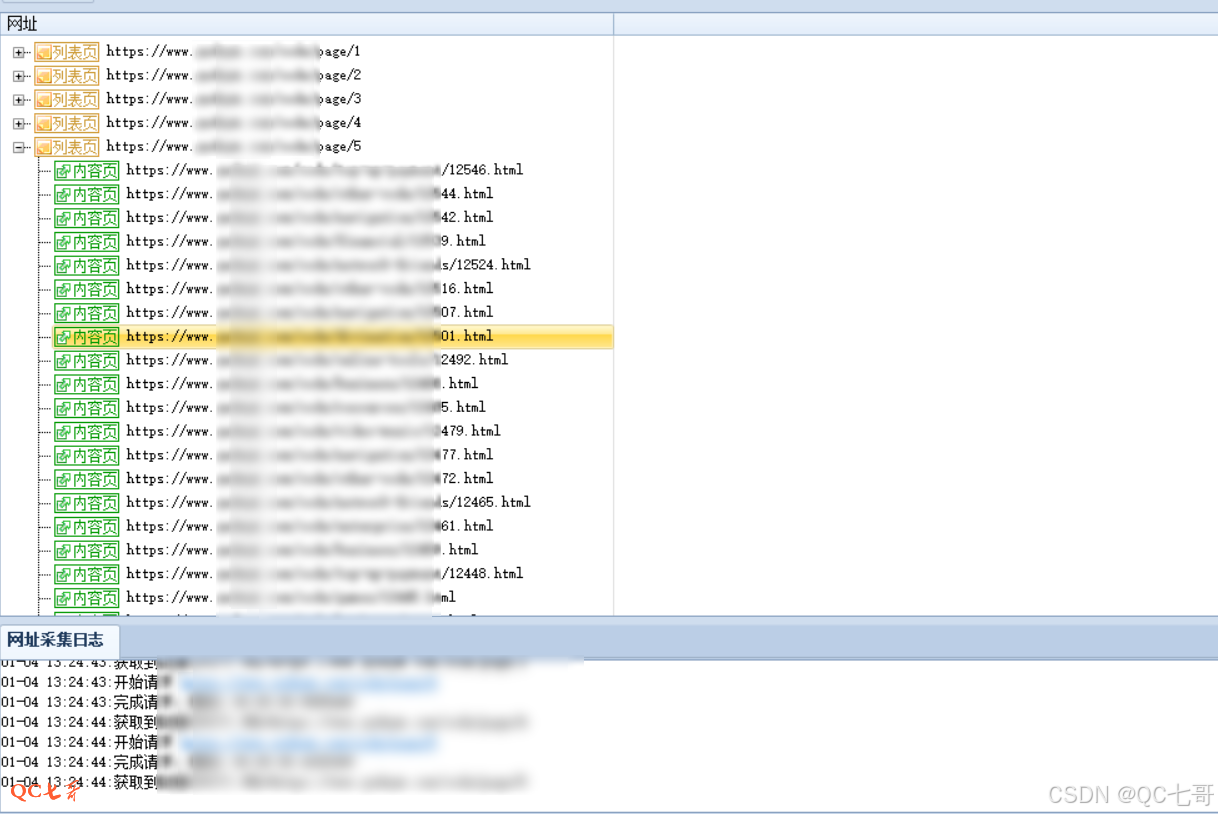
配置好网址采集规则后,点击右下角的网址采集测试,对刚才的配置进行测试看是否正常
测试结果如下(表示当前网址采集规则配置完毕)
2、内容采集规则
(1)文章字段采集
在这里配置采集文章页的所有字段,如标题,时间,作者,文章正文,分类等
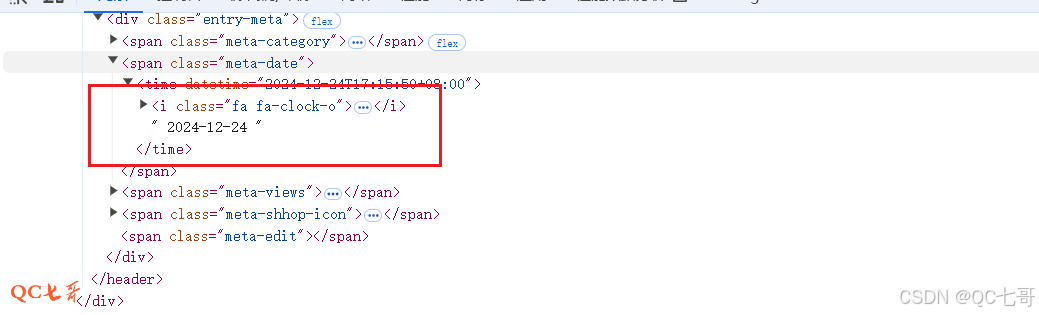
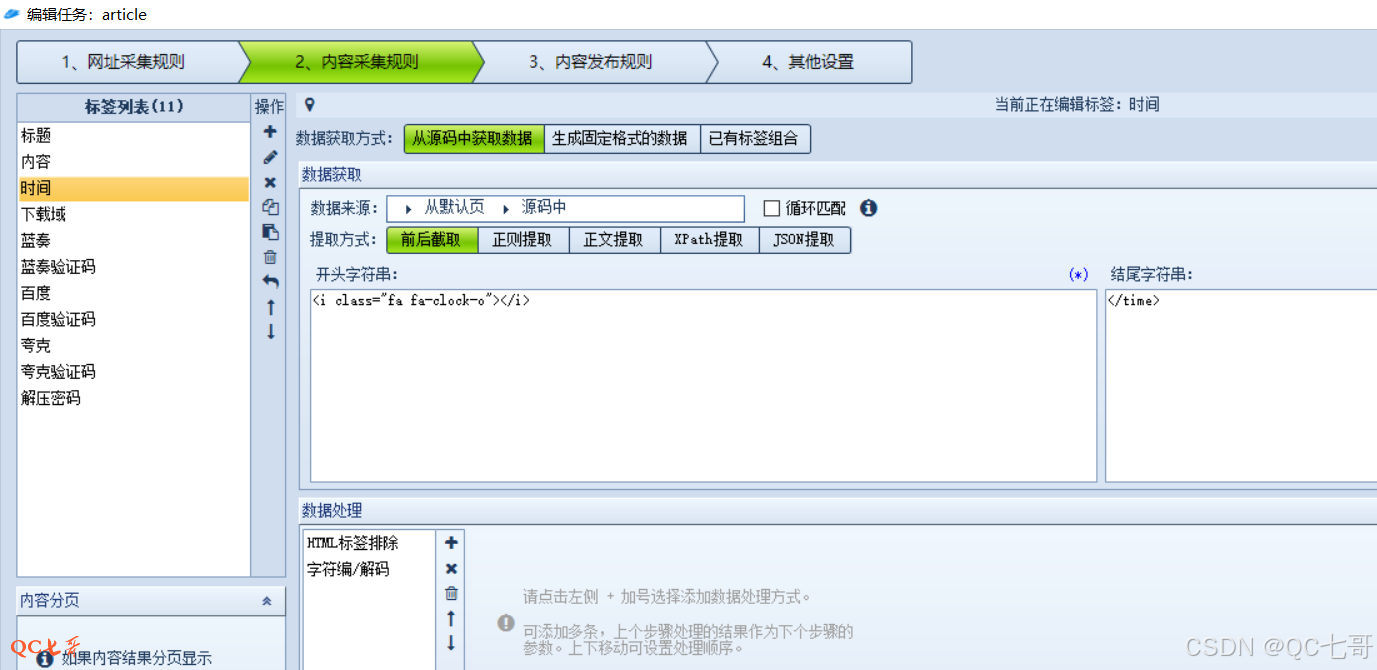
对于大部分字段使用 “前后截取” 就可以得到,如下面时间字段的采集就使用 “前后截取”
对比页面代码,就是将时间字段前的源码拷贝到开头字符串,字段后的源码拷贝到结尾字符串中
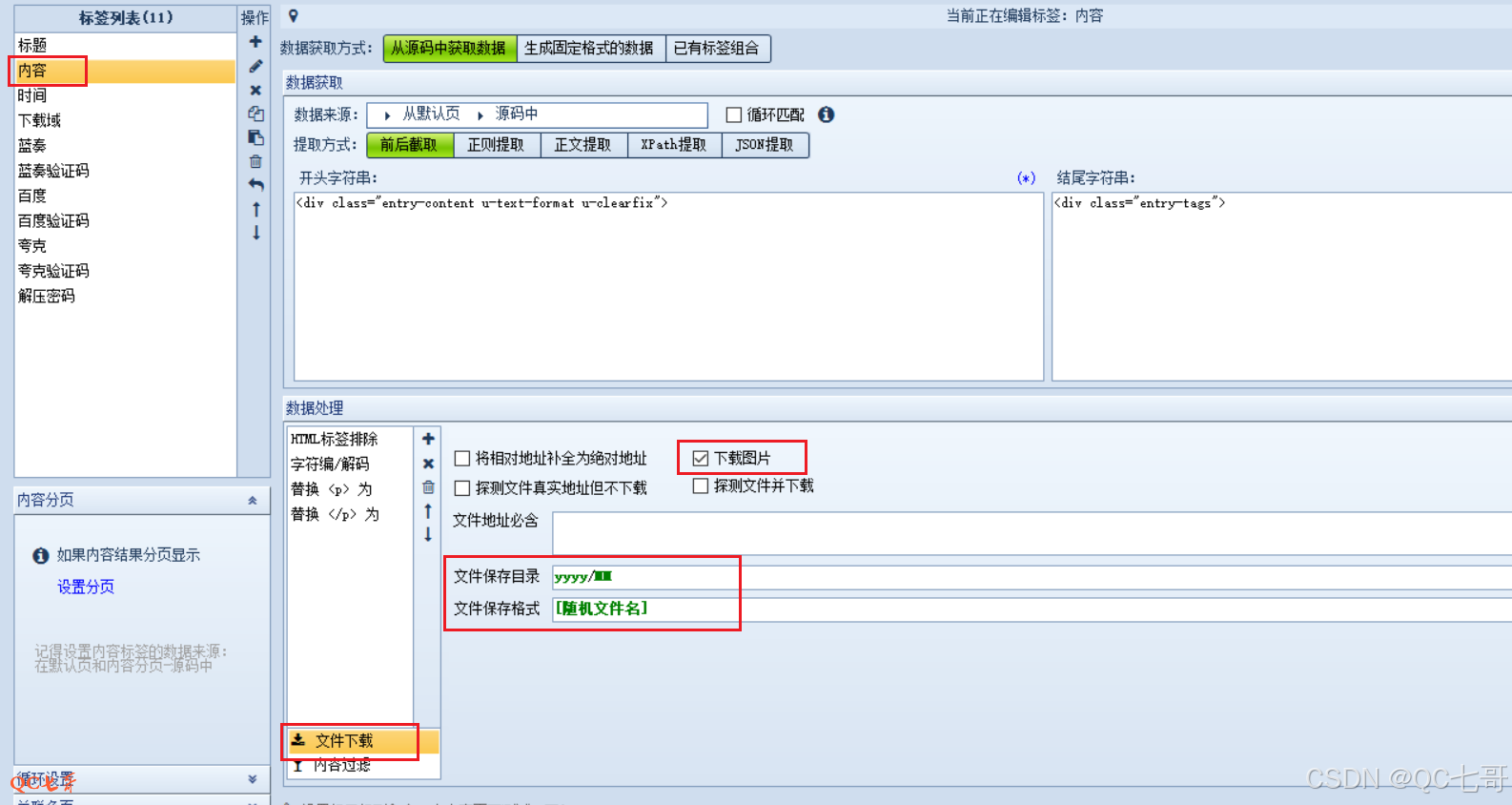
对于更复杂的页面结构,可以使用 xpath 采集并结合插件的方式进行处理
如这里将需要的 “网页代码” 先保存到 “下载域” 字段中,然后使用插件过滤得到每一个字段
可以参考我的另一个文章有介绍 火车头采集插件开发
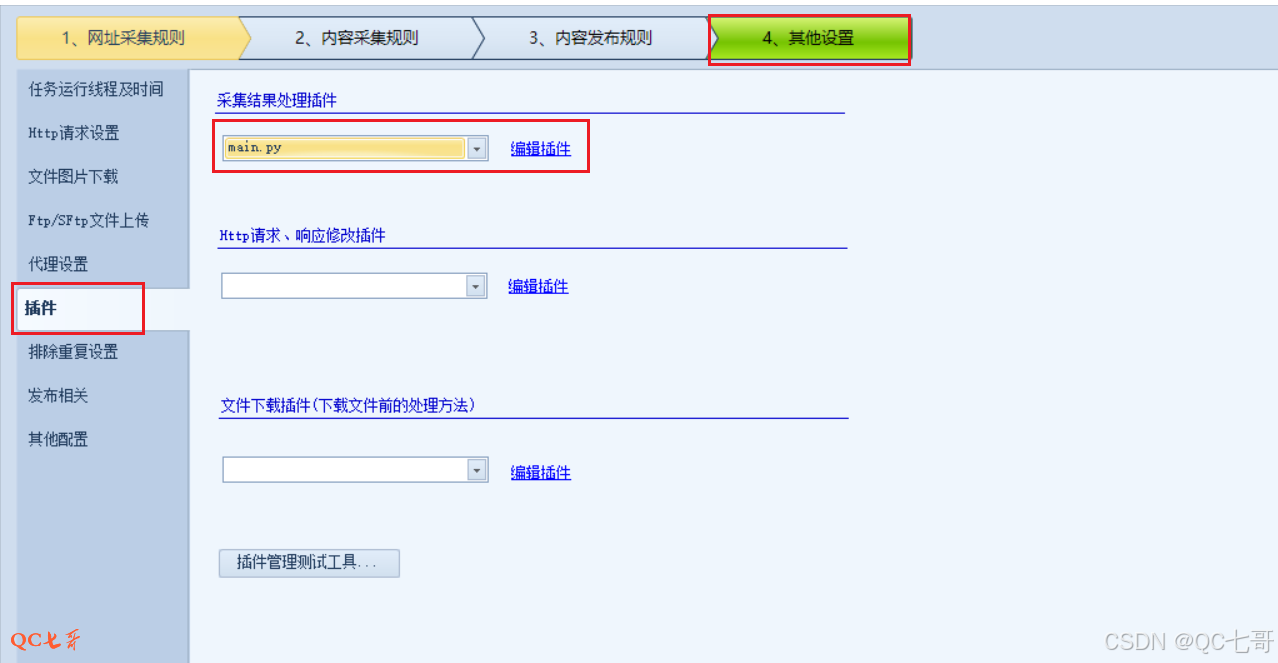
插件编写完毕后,将插件文件拷贝到火车头安装目录下的 Plugins 文件夹中
并在 “其他设置” 中进行选定,如我这里保存的插件文件名为 main.py,设置如下
(2)文章图片采集
通常文章正文都会包含图片,如果不进行处理的话,那么采集到的文章正文中的图片地址还是指向原站
如果原站设置了禁止跨域,那么采集到的文章将无法显示出图片
即便原站没有设置,但是原站图片一旦变动或者删除,也会导致采集的文章图片显示异常
因此,文章中的图片得采集下来,并且还需要将文章中图片的地址修改为正确的地址
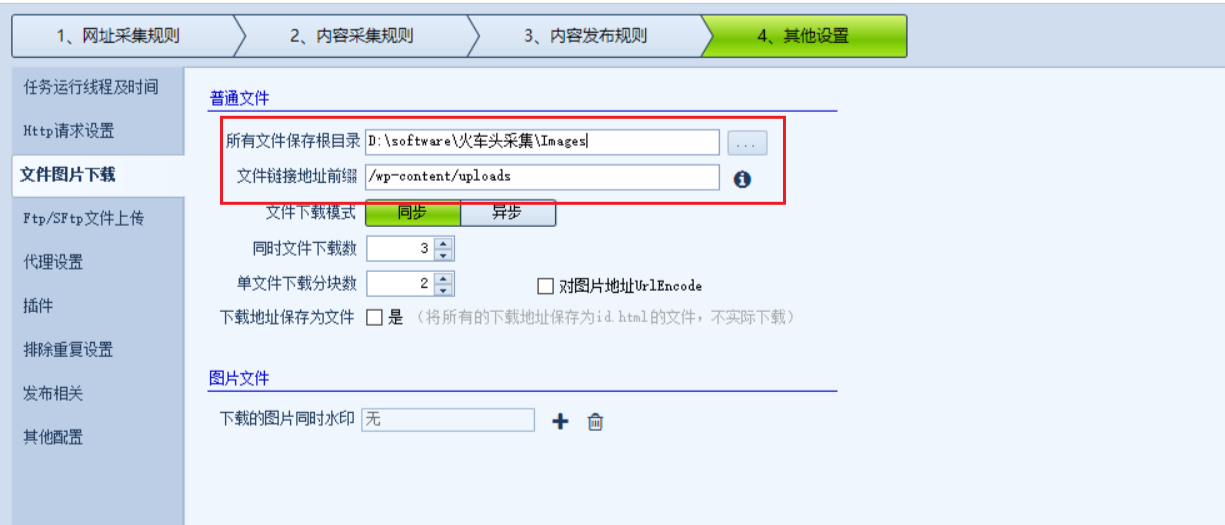
在设置中,添加文件图片下载的目录如下
第一个目录是当前采集下载到本地保存的路径,第二个目录是发布的时候,图片上传站点保存的路径
以我当前的设置为例,在 “内容采集规则” 页面中,设置了文件下载保存目录为 yyyy/MM,那么表示
a、图片下载到本地的目录结构是 D:\software\火车头采集\Images\2025\01
b、文章内容中图片链接前缀被替换为 /wp-content/uploads/2025/01
当图片上传到目标机器中的时候,也需要保持相同的路径(在FTP上传中配置),不然会无法显示图片
这些路径是由几部分配置拼接起来的,这里的 yyyy/MM 对应当前操作时刻的年月为 2025/01
进过上面这些步骤的处理,文章的信息(包括图片)应该都可以正确采集到对应的字段中了
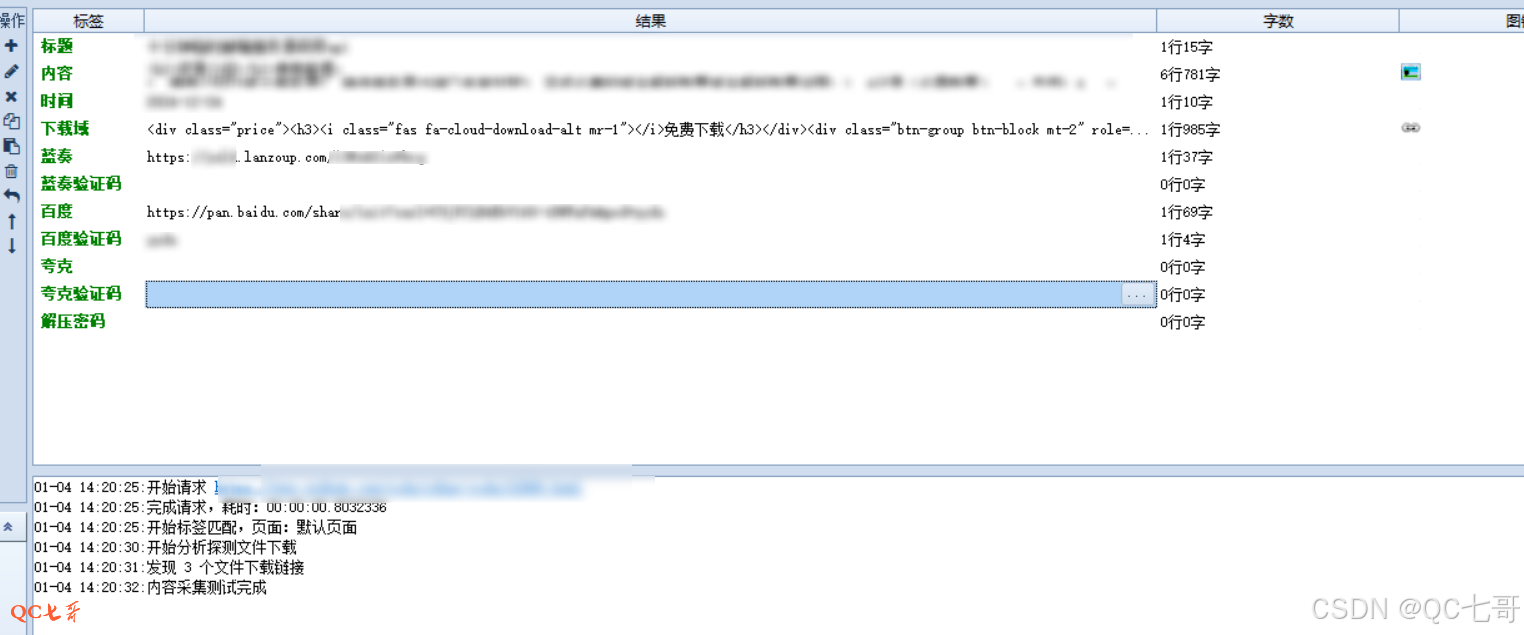
在地址栏中输入一个前面测试时得到的文章地址,然后点击测试,得到所有的字段内容如下

3、内容发布规则
文章太长了,内容发布规则拆分为下一篇文章再补充